V6 AI Extraction Pipeline Evaluation
February 2026
The Metascience Observatory uses a custom pipeline to extract structured replication data from academic papers using AI. We evaluated it against a hand-validated ground truth of 189 effect replication entries across 143 papers, primarily from psychology and related social sciences.
Key results
The pipeline extracted 260 entries total versus 189 in the ground truth. The pipeline got 163 of 189 ground truth entries correct in terms of identifying the reference for the original experiment, a recall of 86%. The pipeline was much more granular than the ground truth, resulting in many extra entries. We believe most of the extra entries were legitimate, but were reporting subanalyses the ground truth annotators decided not to cover. The rest of the extra entries were due to either trouble matching the ground truth rows or due to the pipeline finding a different original study than the ground truth for the same replication.
After a very careful investigation, we determined that the rate of identifying the original study wrongly was 15/260 = 5.8%. We consider identification of the original study reference incorrectly to be a very serious error, and lowering that is a focus going forward. 10/15 of those failures where were the V6 pipeline picked a different paper with some of the same authors as the correct original study.
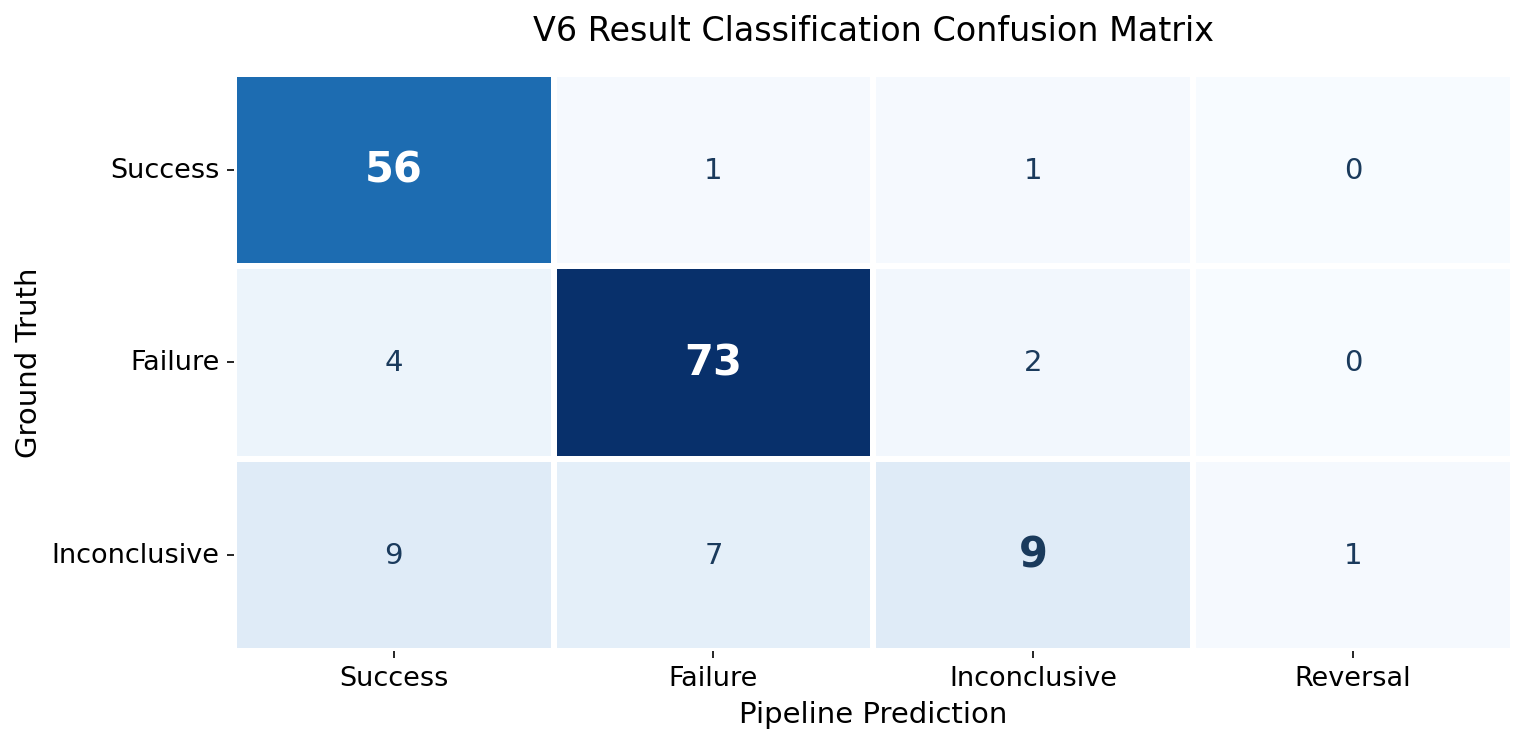
The pipeline classifies each replication as success, failure, or inconclusive. Among the 163 replications it found that matched the ground truth:
| Category | Accuracy |
|---|---|
| Success | 96.6% (56/58) |
| Failure | 92.4% (73/79) |
| Inconclusive | 34.6% (9/26) |
The main difference here is that the pipeline tends to commit to success or failure where human annotators are more likely to go with inconclusive.
Statistical data extraction
The ground truth dataset did not have full coverage of the statistical data in the papers. However, where we had statistical data in the ground truth, the pipeline's extracted values were compared:
| Field | Coverage | Achieved exact match |
|---|---|---|
| Replication sample size | 100.0% (159/159) | 88.1% (140/159) |
| Replication p-value | 100.0% (124/124) | 96.8% (120/124) |
| Replication effect size | 93.6% (102/109) | 87.2% (95/109) |
| Original effect size | 96.9% (93/96) | 89.6% (86/96) |
| Original p-value | 102.3% (45/44) | 97.7% (43/44) |
| Original sample size | 92.0% (103/112) | 80.4% (90/112) |
To improve the pipeline, we designed the V8 pipeline to use more tokens and do a more careful job. Our initial evaluation of the V8 pipeline showed mixed performance compared with V6 - better in some areas, worse in others. Unfortunately, with the creation of our V8 pipeline we created a new type of replication which we call "close - extension". These are replications that attempt to see if an effect generalizes by making a small changes, for instance studying the effect in an Asian population instead of an American population, or studying the effect in children instead of adults. This complicates matching with the ground truth since the ground truth annotators generally did not consider those sort of extensions to be replications, although they did in some cases.